

Zilliz lance Vector Lakebase, étendant la base de données vectorielle la plus utilisée au monde pour en faire une plateforme de données unifiée dédiée à l’IA
Zilliz lance Vector Lakebase, étendant la base de données vectorielle la plus utilisée au monde pour en faire une plateforme de données unifiée dédiée à l’IA
Disponible dès à présent en préversion publique sur Zilliz Cloud, Vector Lakebase conserve au cœur de son offre la recherche vectorielle en production tout en y ajoutant un stockage partagé natif de type lake et des ressources de calcul à la demande, réunissant ainsi la mise à disposition en temps réel, l’exploration interactive et l’analyse par lots au sein d’une même infrastructure de données.
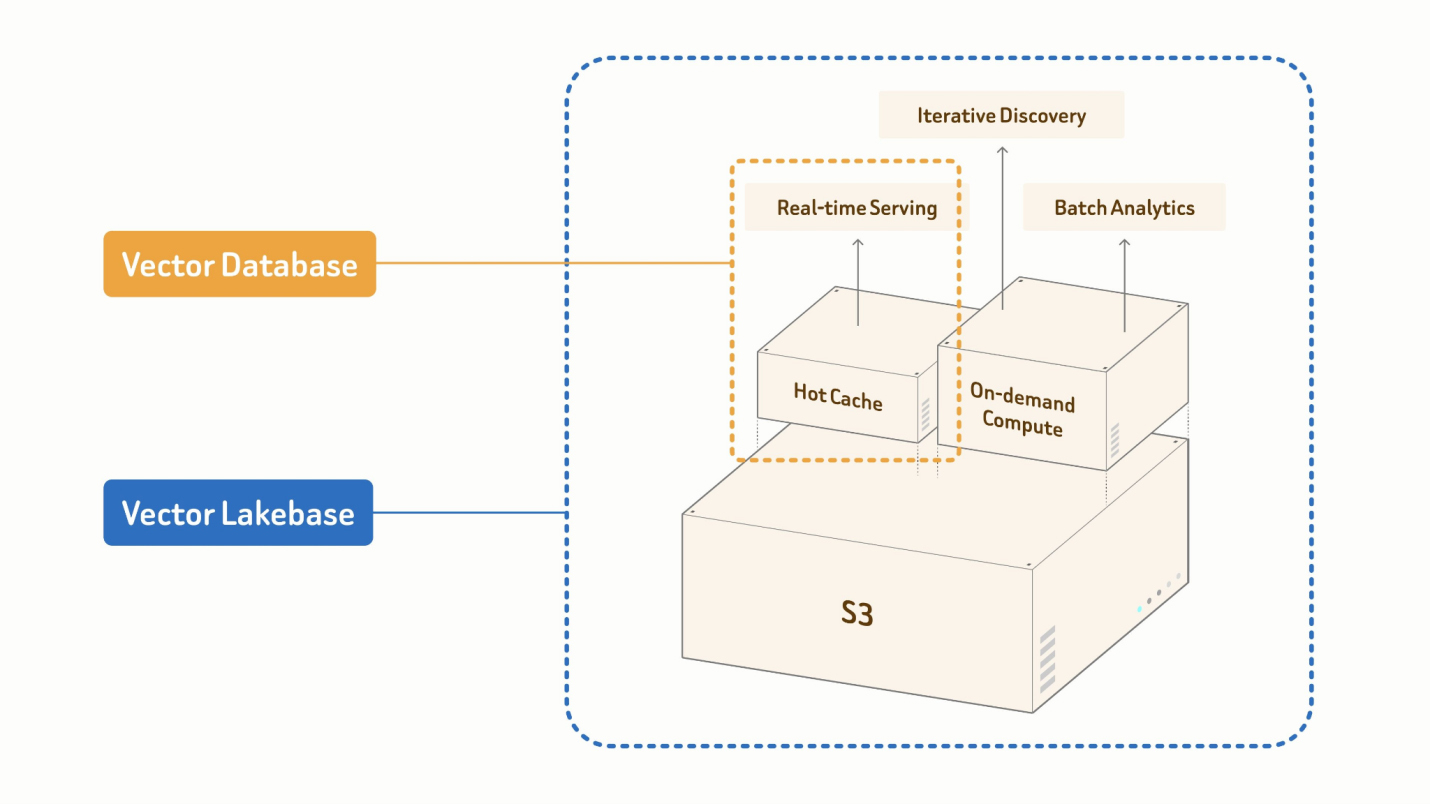
REDWOOD CITY, Californie--(BUSINESS WIRE)--Zilliz, la société à l’origine de Milvus, la base de données vectorielle open source la plus utilisée au monde, a annoncé aujourd’hui la préversion publique de Zilliz Vector Lakebase, une version majeure de Zilliz Cloud qui associe la base de données vectorielle de production à une infrastructure de données partagée et native du lac de données.
Vector Lakebase conserve au cœur de Zilliz Cloud la recherche vectorielle en temps réel le moteur sur lequel s’appuient déjà Zillow, OpenEvidence, Exa, Filevine, MiniMax et plus de 10 000 entreprises et équipes d’IA, et l’étend avec trois nouvelles façons d’exploiter les mêmes données : l’exploration interactive, l’analyse par lots à grande échelle et la recherche directement sur des lacs de données externes. Il en résulte une base de données unique dans laquelle chaque charge de travail s’exécute sur une seule copie logique des données, les tâches à la demande et par lots n’étant facturées que lorsque la puissance de calcul est active.
« La recherche vectorielle en production est et restera au cœur de l’activité de Zilliz, raison pour laquelle des milliers d’équipes choisissent Milvus et Zilliz Cloud, cette technologie gagnant en rapidité et en rentabilité à chaque nouvelle version », déclare Charles Xie, fondateur et directeur général de Zilliz. « Vector Lakebase est, selon nous, la prochaine étape : une base de données unique où les mêmes vecteurs peuvent répondre à une requête en production, servir de point d’ancrage à une session de découverte et alimenter un pipeline de données d’entraînement de plusieurs pétaoctets, sans copies, sans migration ni pile parallèle. »
Pourquoi une base de données unique est essentielle
Les systèmes d’IA ne se résument plus à un simple problème de recherche par requête. Ils fonctionnent en boucle continue, fournissant des résultats, apprenant à partir du retour d’information, exploitant et préparant de meilleures données, puis fournissant à nouveau des résultats, et chaque itération nécessite généralement des systèmes distincts pour la fourniture, l’exploration et le traitement à grande échelle. Le transfert de milliards de vecteurs entre ces systèmes peut prendre plusieurs jours. Le coût et la complexité sont si élevés que de nombreuses équipes renoncent purement et simplement à cette boucle, laissant des données précieuses accessibles, mais jamais améliorées.
Vector Lakebase comble cette lacune grâce à un plan de données sémantique sans copie sur un stockage partagé natif de type lake : la mise à disposition en temps réel, la découverte interactive et l’analyse par lots s’effectuent toutes à partir d’une seule copie logique des données, évoluant de quelques gigaoctets à plusieurs pétaoctets.
« Les équipes recherchaient un moyen de conserver leurs données en un seul endroit et d’y exécuter des charges de travail très différentes, de la mémoire d’agent en temps réel à la déduplication sémantique nocturne », déclare Robert Guo, vice-président des produits chez Zilliz et l’un des architectes à l’origine de Milvus. « Vector Lakebase y parvient grâce à une couche de stockage unifiée sur Vortex, une mise à disposition à plusieurs niveaux pour le chemin de production et une puissance de calcul à la demande pour tout le reste. »
Cinq fonctionnalités sur une seule base
- Service en temps réel à plusieurs niveaux. Trois niveaux de production optimisés pour différentes charges de travail : optimisé pour les performances (plus de 1 000 QPS, latence inférieure à 10 ms, en mémoire) ; optimisé pour la capacité (100 à 500 QPS, latence inférieure à 100 ms, mémoire + NVMe) ; et stockage à plusieurs niveaux (10 à 50 QPS, latence d’environ 100 ms, combinant mémoire, NVMe et stockage objet à un coût nettement inférieur). Tous les niveaux offrent par défaut un taux de récupération de 95 à 98 %, ajustable à plus de 99 %, et s’appuient sur le SLA de Zilliz Cloud garantissant une disponibilité de 99,99 % ainsi que sur la haute disponibilité interrégionale assurée par Global Cluster.
- Recherche à la demande. Ressources de calcul facturées à l’utilisation pour les charges de travail dont l’infrastructure reste inactive la plupart du temps, la facturation portant directement sur le stockage d’objets et les ressources de calcul, sans majoration liée au modèle sans serveur. Dans le test de performance interne de Zilliz portant sur un milliard de vecteurs à 768 dimensions avec 10 heures de calcul actif par mois, la recherche à la demande a coûté au total 318 $ contre 4 937 $ pour une solution sans serveur comparable, soit environ 1/15e du coût.
- Recherche dans un lac de données externe. Un mode de collecte externe zero-copy qui ajoute une indexation de pointe et une recherche à spectre complet directement aux tables Lance, Iceberg, Parquet et Vortex existantes, avec une synchronisation incrémentielle lors de l’actualisation. Les données sources restent à leur emplacement d’origine.
- Recherche IA à spectre complet. Recherche sur des vecteurs (denses et clairsemés), du texte, du JSON et des données géospatiales, avec récupération hybride, BM25, expressions régulières, recherche multivectorielle et itérative, ainsi que récupération multi-chemins. Les résultats peuvent être reclassés à l’aide de Cohere, Voyage AI, RRF et de stratégies de pondération, de renforcement et d’atténuation.
- Stockage unifié basé sur le lac de données. Stockage partagé pour la mise à disposition et l’analyse, basé sur Vortex, un format en colonnes ouvert conçu pour des lectures aléatoires plus rapides et moins coûteuses que Lance et Parquet, associé à des index adaptés au stockage objet (vecteur, BM25, JSON) qui réduisent l’amplification des lectures de plus de 90 %. Le remplissage d’un schéma de 100 millions de lignes s’effectue généralement en quelques minutes, sans perturber le trafic de requêtes en cours.
Ensemble, ces capacités permettent aux équipes d’IA de regrouper sur une seule plateforme ce qui nécessitait auparavant des clusters de service parallèles fonctionnant en permanence et des systèmes de traitement par lots distincts, avec des index cohérents, des données versionnées et une puissance de calcul qui s’adapte à zéro entre les tâches.
Disponibilité
Zilliz Vector Lakebase est désormais disponible en préversion publique sur Zilliz Cloud, avec des options de déploiement sans serveur, dédiées et BYOC (apportez votre propre infrastructure) dans plus de 30 régions sur AWS, Google Cloud et Microsoft Azure. Les nouvelles inscriptions avec un e-mail professionnel bénéficient de 100 $ de crédits gratuits sur zilliz.com. Les équipes qui exécutent des opérations de service, de découverte et d’analyse sur des piles distinctes peuvent contacter l’équipe Zilliz pour bénéficier d’une présentation personnalisée.
À propos de Zilliz
Zilliz est une entreprise leader dans le domaine des infrastructures de données pour l’IA et le créateur de Milvus, la base de données vectorielle open source la plus largement adoptée au monde, avec plus de 44 000 étoiles sur GitHub et plus de 100 millions de pulls Docker. Zilliz aide les entreprises et les startups spécialisées dans l’IA à rendre leurs données non structurées consultables, analysables et gérables, transformant ainsi le texte, les images, l’audio, la vidéo et bien plus encore en un atout stratégique pour l’IA en production.
La technologie de Zilliz s’articule autour de Milvus et de Zilliz Cloud. Milvus est une base de données vectorielle open source spécialement conçue pour la recherche vectorielle à l’échelle de 100 milliards d’entrées. Zilliz Cloud étend cette base pour en faire une plateforme Vector Lakebase entièrement gérée, combinant les capacités de service à haut débit et à faible latence des bases de données vectorielles avec l’ouverture, l’évolutivité et la rentabilité des lacs de données multimodaux. Zilliz accompagne plus de 10 000 entreprises et startups spécialisées dans l’IA à travers le monde, notamment MiniMax, OpenEvidence, Filevine, Exa, Salesforce et Read AI.
Basée à Redwood Shores, en Californie, Zilliz bénéficie du soutien d’investisseurs de premier plan, notamment Prosperity 7 Ventures (filiale d’Aramco), Pavilion Capital (filiale de Temasek), Hillhouse Capital, 5Y Capital, Yunqi Partners et Trustbridge Partners. Pour en savoir plus, rendez-vous sur Zilliz.com.
Le texte du communiqué issu d’une traduction ne doit d’aucune manière être considéré comme officiel. La seule version du communiqué qui fasse foi est celle du communiqué dans sa langue d’origine. La traduction devra toujours être confrontée au texte source, qui fera jurisprudence.
Contacts
Contact médias
Molly Chen
molly.chen@zilliz.com
+1 951-265-1426
