

Zilliz lanciert Vector Lakebase und erweitert die weltweit am meisten implementierte Vektordatenbank zu einer einheitlichen Datenplattform für KI
Zilliz lanciert Vector Lakebase und erweitert die weltweit am meisten implementierte Vektordatenbank zu einer einheitlichen Datenplattform für KI
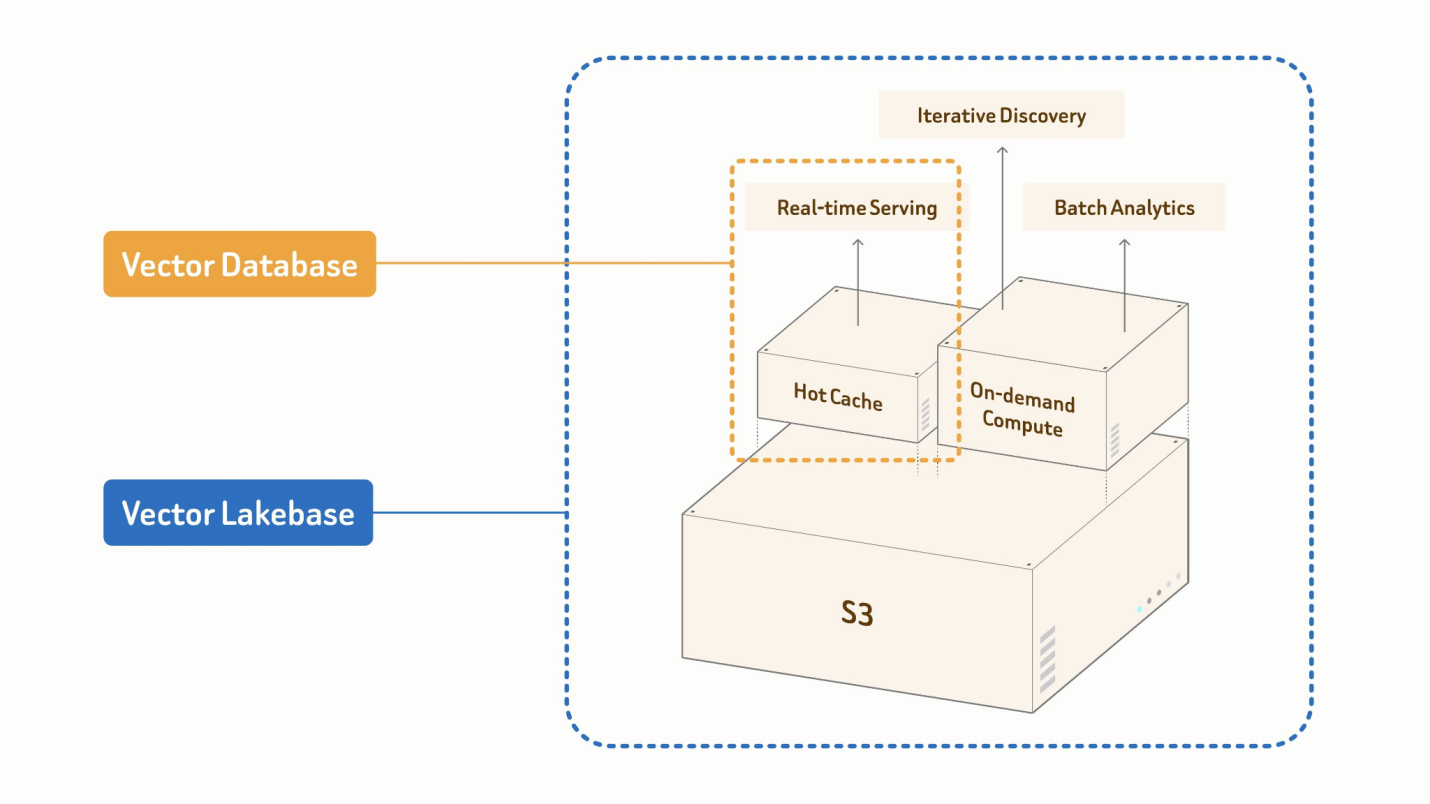
Im Mittelpunkt von Vector Lakebase steht die Vektorsuche in der Produktion, ergänzt um gemeinsamen Lake-nativen Speicher und On-Demand-Computing. Damit werden Echtzeit-Bereitstellung, interaktive Exploration und Batch-Analysen auf eine zentrale Datengrundlage gebracht. Die öffentliche Vorschau ist jetzt auf Zilliz Cloud verfügbar.
REDWOOD CITY, Kalifornien--(BUSINESS WIRE)--Zilliz, das Unternehmen hinter Milvus, der weltweit am meisten implementierten Open-Source-Vektordatenbank, gab heute die öffentliche Vorschau von Zilliz Vector Lakebase, einer Major Release von Zilliz Cloud, bekannt, in der die Vektordatenbank für die Produktion mit einer gemeinsamen Lake-nativen Datengrundlage gepaart wird.
Im Mittelpunkt von Vector Lakebase steht die Echtzeit-Vektorsuche von Zilliz Cloud, mit der Engine, auf die sich Zillow, OpenEvidence, Exa, Filevine, MiniMax und mehr als 10.000 Unternehmen und KI-Teams verlassen, ergänzt um drei neue Optionen zur Verarbeitung derselben Daten: interaktive Exploration, umfangreiche Batch-Analysen und Suche direkt in externen Data Lakes. Dadurch ergibt sich eine zentrale Datengrundlage, in der jeder Workflow an einer einzelnen logischen Kopie der Daten ausgeführt wird, wobei On-Demand- und Batch-Jobs nur bei aktivem Computing in Rechnung gestellt werden.
„Die Vektorsuche in der Produktion steht bei Zilliz im Mittelpunkt, und das wird auch so bleiben. Sie ist der Grund, warum tausende von Teams Milvus und Zilliz Cloud wählen, und mit jeder Release wird sie schneller und kosteneffizienter“, sagte Charles Xie, Gründer und CEO von Zilliz. „Vector Lakebase ist unserer Meinung nach der nächste Schritt: eine zentrale Datengrundlage, wobei dieselben Vektoren eine Produktionsabfrage bereitstellen, eine Explorationssitzung einrichten und eine Trainingsdaten-Pipeline im Multi‑Petabyte‑Bereich unterstützen können – und zwar ohne Kopien, Migration oder paralleler Stack.
Warum eine zentrale Datengrundlage wichtig ist
Bei KI-Systemen geht es nicht mehr um die Beantwortung einer einzelnen Abfrage. Sie bilden eine fortlaufende Schleife, die Antworten bereitstellen, durch Feedback lernen, bessere Daten auswerten und vorbereiten und dann erneut Antworten bereitstellen. Für Bereitstellung, Exploration und umfangreiche Verarbeitung werden in der Regel separate Systeme benötigt. Das Verschieben von Milliarden von Vektoren zwischen diesen Systemen kann Tage dauern. Die damit verbundenen Kosten und Komplexität sind so hoch, dass viele Teams diesen Prozess einfach überspringen. So können zwar wertvolle Daten abgerufen werden, sie werden jedoch nicht optimiert.
Vector Lakebase schließt diese Lücke mit einer semantischen Datenebene in Lake-nativem Speicher, die ohne Kopien auskommt. Echtzeit-Bereitstellung, interaktive Exploration und Batch-Analysen werden an einer zentralen logischen Kopie der Daten ausgeführt, die sich von Gigabyte bis auf Petabyte skalieren lässt.
„Teams wollten eine Möglichkeit, ihre Daten an einer Stelle zu halten und sehr unterschiedliche Workloads für sie auszuführen – von Echtzeit-Agent-Speicher bis hin zu semantischer Deduplizierung über Nacht“, sagte Robert Guo, VP of Product bei Zilliz und einer der Architekten hinter Milvus. „Vector Lakebase ermöglicht dies über einen einheitlichen Speicher-Layer auf Vortex, gestaffelte Bereitstellung für den Produktionspfad und On-Demand-Computing für alles andere.“
Fünf Funktionen auf einer Grundlage
- Gestaffelte Echtzeit-Bereitstellung. Drei Produktions-Tiers, die für unterschiedliche Workloads optimiert sind: Leistungsoptimiert (1.000+ QPS, Latenz im einstelligen Millisekunden-Bereich, In-Memory); kapazitätsoptimiert (100–500 QPS, Latenz von unter 100 ms, Arbeitsspeicher+ NVMe) und Tiered-Storage (10–50 QPS, Latenz von ~100 ms, Arbeitsspeicher, NVMe und Objektspeicher zu deutlich geringeren Kosten). Alle Tiers weisen standardmäßig einen Recall von 95 bis 98 % auf, können auf mehr als 99 % konfiguriert werden, werden durch die SLA von Zilliz Cloud für eine Betriebszeit von 99,99 % und regionsübergreifende hohe Verfügbarkeit von Global Cluster gestützt.
- On-Demand-Suche. Pay-as-you-Go-Computing für Workloads, bei denen die Infrastruktur meistens untätig ist, direkte Abrechnung für Objektspeicher und Computing anstatt serverlosen Markups. In der internen Benchmark von Zilliz zu einer Milliarde 768‑dimensionalen Vektoren mit 10 Stunden aktivem Computing pro Monat belief sich die On-Demand-Suche auf 318 USD, gegenüber 4.937 USD für einen vergleichbaren serverlosen Pfad. Das entspricht etwa 1/15 der Kosten.
- Externe Data-Lake-Suche. Ein externer Erfassungsmodus, der ohne Kopien auskommt, bei dem bestehende Lance-, Iceberg-, Parquet- und Vortex-Tabellen um modernste Indexierung und Vollspektrum-Suche ergänzt werden, mit inkrementeller Synchronisierung bei der Aktualisierung. Die Quelldaten bleiben an ihrem gewohnten Ort.
- Vollspektrum-KI-Suche. Suche über Vektoren (dicht und dünn besetzt), Text, JSON- und raumbezogene Daten mit hybridem Abruf, BM25, regulären Ausdrücken, Multi-Vektor- und iterativer Suche sowie Multi-Path-Abruf. Die Ergebnisse lassen sich mit Cohere, Voyage AI, RRF und Strategien für Gewichtung/Verstärkung/Abschwächung neu klassifizieren.
- Einheitlicher Lake-nativer Speicher. Gemeinsamer Speicher für Bereitstellung und Analyse basierend auf Vortex, einem offenen Spaltenformat, das auf schnellere, kostengünstigere Lesevorgänge ausgelegt ist als Lance und Parquet, gepaart mit objektspeicherbewussten Indizes (Vektor, BM25, JSON), die die Leseverstärkung um mehr als 90 % reduzieren. Ein Schema-Backfill mit 100 Millionen von Zeilen wird in der Regel innerhalb von wenigen Minuten abgeschlossen, ohne aktiven Abfrage-Traffic zu unterbrechen.
Gemeinsam ermöglichen es diese Funktionen KI-Teams, das, wofür zuvor parallele Always-on-Bereitstellungscluster und separate Batch-Systeme erforderlich waren, auf einer Plattform zu konsolidieren – mit konsistenten Indizes, versionierten Daten und Computing, das sich zwischen Jobs auf null skalieren lässt.
Verfügbarkeit
Zilliz Vector Lakebase ist jetzt in der öffentlichen Vorschau auf Zilliz Cloud verfügbar, neben serverlosen, dedizierten und BYOC-Bereitstellungsoptionen in mehr als 30 Regionen auf AWS, Google Cloud und Microsoft Azure. Bei Registrierung neuer geschäftlicher E-Mail-Adressen erhalten Sie 100 USD kostenloses Guthaben auf zilliz.com. Teams, die Bereitstellung, Exploration und Analysen auf separaten Stacks vornehmen, können sich an das Team von Zilliz wenden, um eine personalisierte Vorstellung zu erhalten.
Über Zilliz
Zilliz ist ein führender Anbieter von KI-Dateninfrastruktur und Entwickler von Milvus, der weltweit am meisten implementierten Open-Source-Vektordatenbank mit über 44.000 GitHub-Sternen und mehr als 100 Millionen Docker Pulls. Zilliz hilft Unternehmen und KI-Startups dabei, ihre unstrukturierten Daten durchsuchbar, analysierbar und steuerbar zu machen, um Text, Bilder, Audio- und Videoinhalte und mehr in strategische Assets für Produktions-KI zu verwandeln.
Im Mittelpunkt der Technologie von Zilliz stehen Milvus und Zilliz Cloud. Milvus ist eine Open-Source-Vektordatenbank, die speziell für die Vektorsuche im Bereich von 100 Milliarden Vektoren entwickelt wurde. Zilliz Cloud erweitert diese Grundlage auf eine vollständig verwaltete Vector Lakebase-Plattform, die die Bereitstellungskapazitäten von Vektordatenbanken, die sich durch hohen Durchsatz und niedrige Latenz auszeichnen, mit der Offenheit, Skalierbarkeit und Wirtschaftlichkeit multimodaler Data Lakes kombiniert. Zilliz bedient weltweit mehr als 10.000 Unternehmen und KI-native Startups, darunter MiniMax, OpenEvidence, Filevine, Exa, Salesforce und Read AI.
Zilliz, dessen Hauptsitz in Redwood Shores, Kalifornien liegt, wird von führenden Investoren unterstützt, darunter Prosperity 7 Ventures von Aramco, Pavilion Capital von Temasek, Hillhouse Capital, 5Y Capital, Yunqi Partners und Trustbridge Partners. Weitere Informationen finden Sie auf Zilliz.com.
Die Ausgangssprache, in der der Originaltext veröffentlicht wird, ist die offizielle und autorisierte Version. Übersetzungen werden zur besseren Verständigung mitgeliefert. Nur die Sprachversion, die im Original veröffentlicht wurde, ist rechtsgültig. Gleichen Sie deshalb Übersetzungen mit der originalen Sprachversion der Veröffentlichung ab.
Contacts
Medienkontakt
Molly Chen
molly.chen@zilliz.com
+1 951-265-1426
