Networking Chip Startup Enfabrica Emerges from Stealth Mode to Solve Scalability and Price-Performance Challenges for AI Growth in Cloud
Networking Chip Startup Enfabrica Emerges from Stealth Mode to Solve Scalability and Price-Performance Challenges for AI Growth in Cloud
Reveals Groundbreaking Accelerated Compute Fabric Devices and Solutions at MemCon 2023, Enabling 50% Lower Cost of Compute and 50X Memory Expansion in AI Clusters
MOUNTAIN VIEW, Calif.--(BUSINESS WIRE)--Enfabrica Corporation, a startup building leading-edge networking silicon and software tailored to the needs of fast-evolving Artificial Intelligence (AI) and accelerated computing workloads, today emerged from stealth mode to announce a revolutionary new class of chips— called Accelerated Compute Fabric (ACF) devices. ACF devices deliver unmatched scalability, performance and total cost of ownership (TCO) for distributed AI, machine learning, extended reality, high-performance computing and in-memory database infrastructure. Enfabrica will showcase its ACF solution and its ability to solve the most critical I/O and memory scaling problems for data center AI and accelerated compute at this year’s inaugural MemCon Conference, taking place March 28-29 in Mountain View, Calif.
Enfabrica Launch Highlights:
- Enfabrica began in 2020, funded by Sutter Hill Ventures, and led by Silicon Valley veterans Rochan Sankar, Shrijeet Mukherjee, and key engineers who built industry-leading silicon and software stacks at Broadcom, Google, Cisco, AWS and Intel.
- Enfabrica’s ACF solution was invented and developed from the ground up to solve the scaling challenges of accelerated computing– enabling businesses to meet the exponentially increasing data demands of an AI-driven services economy.
-
Enfabrica’s new, innovative ACF devices:
- Deliver scalable, streaming, multi-Terabit-per-second data movement between GPUs, CPUs, accelerators, memory and networking devices.
- Employ hardware and software interfaces that are 100 percent standards based.
- Collapse tiers of latency and optimize out interface bottlenecks in today’s Top-of-Rack network switches, server NICs, PCIe switches and CPU-controlled DRAM.
- Enable composable AI fabrics of compute, memory and network resources, from a single system to tens of thousands of nodes.
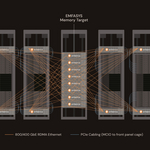
- Provide uncontended access to >50X DRAM expansion over existing GPU networks via ComputeExpressLink (CXL) bridging.
- Enfabrica’s flagship ACF switch silicon enables customers to cut their cost of GPU compute by an estimated 50 percent for Large Language Model (LLM) inferencing and 75 percent for deep learning recommendation model (DLRM) inferencing at the same performance point.
- According to 650 Group, the data center silicon spend on high-performance I/O across compute, storage and networking chips is expected to double to over $20 billion by 2027.
“Generative AI is rapidly transforming the nature and volume of compute traffic in data centers,” said Rochan Sankar, CEO and co-founder of Enfabrica. “AI problem sizes and user serving scale will continue to grow by orders of magnitude every couple of years. The problem is that current server I/O and networking solutions have serious bottlenecks that will cause them to either buckle under the scale of demand, or vastly underutilize the costly compute resources deployed to meet it. We believe we have cracked the code on a I/O fabric design that will scale high-performance, low-latency AI workloads at far superior TCO than anything out there, and make growing AI infrastructure composable, sustainable and democratized. We are excited to work with our partners and target customers to deliver our Accelerated Compute Fabric products into this fast evolving market.”
More about the Accelerated Compute Fabric solution
Enfabrica’s first chip, the Accelerated Compute Fabric Switch (ACF-S), developed clean-sheet by the company since 2020, employs entirely standards-based hardware and software interfaces, including multi-port 800 Gigabit Ethernet networking and high-radix PCIe Gen5 and CXL 2.0+ interfaces. ACF-S devices deliver scalable, composable, high-bandwidth data movement between any combination of GPU, CPU, accelerator ASIC, memory, flash storage and networking elements participating in an AI or accelerated computing workload.
Without changing physical interfaces, protocols or software layers above device drivers, the ACF-S delivers multi-Terabit switching and bridging between heterogeneous compute and memory resources in a single silicon die, while dramatically reducing the number of devices, I/O latency hops, and device power in today’s AI clusters consumed by top-of-rack network switches, RDMA-over-Ethernet NICs, Infiniband HCAs, PCIe/CXL switches, and CPU-attached DRAM.
By incorporating unique CXL memory bridging capabilities, Enfabrica’s ACF-S is the first data center silicon product in the industry to deliver headless memory scaling to any accelerator, enabling a single GPU rack to have direct, low-latency, uncontended access to local CXL.mem DDR5 DRAM at more than 50 times greater memory capacity versus GPU-native High-Bandwidth Memory (HBM).
Addressing Critical Scaling and TCO Challenges of AI Infrastructure
Generative AI and Large Language Models (LLMs) are now driving the largest infrastructure push in cloud computing. This forces the largest pressure for cost and power efficiency on being able to sustain growth of user interactions (i.e. inference serving) on the lowest possible number of GPUs and processors.
Applying Enfabrica’s Accelerated Compute Fabric solution with CXL memory to generative AI workloads enables massively parallel dynamic dispatch of user contexts to GPUs. Simulation results show the ACF-enabled system achieves the same target inference performance using only half the number of GPUs and CPU hosts compared to the latest “bigiron” GPU servers in the market.
Enfabrica’s ACF-S similarly slashes the cost of compute for large-scale AI recommendation engines. On an exemplary hyperscale DLRM inference load, the solution’s memory tiering is shown to cut down the required number of GPUs and CPUs by 75%-- a disruptive TCO and power advantage.
“Scaling memory bandwidth and capacity is a critical need for accelerated computing in the cloud,” said Bob Wheeler, principal analyst at Wheeler’s Network. “In this light, we see CXL and RDMA as complementary technologies, with hyperscalers having already deployed high-bandwidth RDMA networks for GPUs. Enfabrica’s unique blending of CXL switching and RDMA networking functions in a single Accelerated Compute Fabric device promises a disruptive way to build scalable memory hierarchies for AI, and importantly the solution doesn’t have to rely on advanced CXL 3.x capabilities that are years away from being implemented or proven at scale.”
Wheeler’s Network and Enfabrica have jointly released a white paper, “The Evolution of Memory Tiering at Scale” by Bob Wheeler, which provides a detailed view of CXL technologies, memory expansion, pooling and tiering, and the role of RDMA networking in advanced data centers. An online version of the white paper is published here.
About Enfabrica
Enfabrica is an emerging silicon and software company building the foundational fabric technologies for the age of AI. Its groundbreaking chips, software and enabled systems are designed to solve critical I/O bottlenecks in accelerated computing infrastructure, at any scale. Enfabrica is unleashing the revolution in next-gen computing with the world’s most advanced, performant, and efficient solutions interconnecting compute, memory, and network. Because the fabric is the computer.
To learn more, follow us on LinkedIn or visit enfabrica.net.
Third-party trademarks mentioned are the property of their respective owners.
Contacts
Nick Gibiser for Enfabrica
Wireside Communications
Email: ngibiser@wireside.com
Phone: +1-804-500-6660