Varada Can Now Seamlessly, Yet Dramatically, Accelerate Queries on Trino (PrestoSQL), Enabling Data Teams to Leverage the Power of Big Data Indexing
Varada Can Now Seamlessly, Yet Dramatically, Accelerate Queries on Trino (PrestoSQL), Enabling Data Teams to Leverage the Power of Big Data Indexing
New Varada feature brings query acceleration technology directly to existing Trino clusters, via a seamless connector deployment.
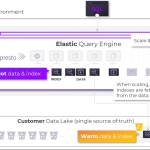
TEL AVIV, Israel--(BUSINESS WIRE)--Varada, a data lake query acceleration innovator, today made available a new feature enabling data teams to accelerate by 10x-100x queries running on Trino clusters (formerly known as PrestoSQL), directly on the data lake. This new capability follows Varada’s product launch in late 2020. In addition to the option to deploy Varada as an independent data lake analytics platform, Varada can now be deployed alongside existing Trino clusters and seamlessly apply its dynamic and adaptive indexing-based acceleration technology. SQL queries can continue running as is, with no additional configurations. It is currently available on AWS and is compatible with all Trino and previous PrestoSQL versions.
“Varada learns and analyzes Trino workloads to apply the optimal cache and indexing strategy autonomously,” explained Eran Vanounou, CEO at Varada. “Enabling Trino clusters to leverage Varada’s acceleration is as simple as installing a .JAR file to the nodes. Any query using presto-hive to access the data lake, such as S3 or HDFS, can benefit from Varada’s unprecedented query performance.”
With the Varada, data teams can:
- Accelerate queries up to 100 times faster compared to direct data lake access
- Expand operational data instantaneously and eliminate the need for preparation, movement, or modeling to meet near real-time query performance requirements
- Obtain deep and actionable insights on all clusters, including critical workload-level observability
“From a business standpoint, Varada also adds a workload-level observability layer for Trino clusters, which is the key to understanding how queries perform and how business requirements are met,” said Vanounou. “The ability to augment existing Trino clusters results in faster, more predictable performance, which only improves the customer’s experience and increases their satisfaction.”
Supporting Trino’s Momentum and Strong Community
Trino is an open source distributed SQL query engine that allows for querying data right where it lives. Among other advantages, Trino can run analytic queries against any size of data source. Trino’s robustness, favorable reputation and status as an open source solution has led Varada and many others to rely on Trino for their querying needs.
Varada has remained committed to the Trino and PrestoDB communities and has already made available its Presto Workload Analyzer as a standalone, open source tool to help Presto administrators optimize their Presto clusters independently. Varada’s Data Platform, runs an indexing-based acceleration engine to accelerate queries for fast analytics on thousands of dimensions and trillions of rows. The platform is already available for use on AWS and supports compatibility with any version of Trino. It will soon be compatible with PrestoDB, along with expected availability on Google Cloud Platform and Azure clusters.
About Varada
The Varada mission is to enable data practitioners to go beyond the traditional limitations imposed by data infrastructure and instead zero in on the data and answers they need—with complete control over performance, cost and flexibility. In Varada's world of big data, every query can find its optimal plan, with no prior preparation and no bottlenecks, providing consistent performance at a petabyte scale. Varada was founded by veterans of the Dell EMC XtremIO core team, and is dedicated to leveraging the data lake architecture to take on the challenge of data and business agility. Varada has been recognized in the Cool Vendors in Data Management report by Gartner, Inc. For more information, visit: https://varada.io/
Contacts
Robert Cathey
Cathey Communications for Varada
robert@cathey.co
+1 865.386.6118