

Varada Ships Version 3.0, Adding Elastic Scaling to the Power of Indexing for Big Data Analytics, Extending TCO and Performance Advantages
Varada Ships Version 3.0, Adding Elastic Scaling to the Power of Indexing for Big Data Analytics, Extending TCO and Performance Advantages
Latest version delivers elastic scaling without sacrificing the power of indexing by separating compute and storage.
TEL AVIV, Israel--(BUSINESS WIRE)--Varada, the data lake query acceleration innovator, today unveiled version 3.0 of its data analytics platform, now delivering a powerful and cost-effective alternative to offerings like Snowflake, Redshift, Athena, Preso, Trino and BigQuery for at-scale big data analytics users who rely on the power of indexing to extract insights from massive, unstructured data sets.
The new version marries the power of cloud elasticity and the query power of indexing for big data analytics, giving data teams the ability to scale analytics workloads rapidly and meet fluctuating demand. It delivers a dramatic increase in cost performance and cluster elasticity as compared to the previous version. In addition, version 3.0 eliminates the need to keep high-performance and expensive SSD NVMe (Solid-State Drive Nonvolatile Memory Express) compute instances idling when the cluster is not in use.
Data teams are often evaluated on how quickly they can react to spikes in demand. The separation of compute and storage in version 3.0 lets them elastically scale clusters out and in as query traffic fluctuates, avoiding the waste of overprovisioning and idle resources.
“Varada was built on the premise that indexing can transform big data analytics, if done correctly,” said Eran Vanounou, CEO of Varada. “With version 3.0, the Varada platform is now the most powerful and cost-effective way to leverage the power of big data directly atop your data lake.”
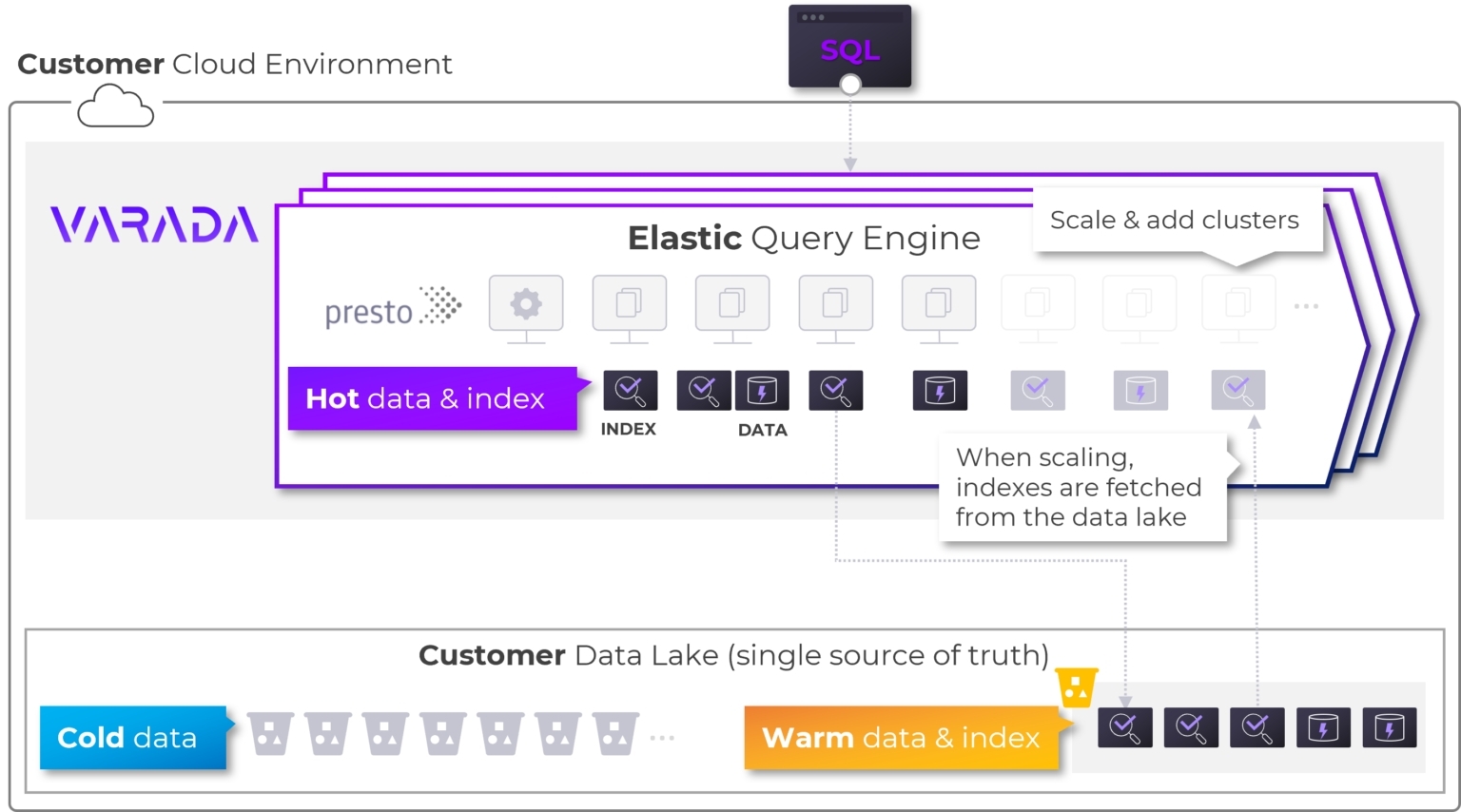
“Query acceleration optimizations are time consuming to create, including indexing,” continued Vanounou. “So, we want to ensure that the platform operates autonomously, including quickly reacting to changing demand. V 3.0 introduces a new layer to Varada’s platform. We’ve separated the index and data from the SSD nodes, creating a “warm” tier in the data lake that allows us to preserve those indexes much faster and at a much lower cost. By doing so we’re bringing the power of cloud computing scaling to big data indexing.”
Big Data Indexing Must Be Autonomous (Adaptive, Dynamic and Elastic)
This third iteration of the Varada platform marks the latest step in a journey that began last December with version 1.0, in which adaptive indexing chooses the optimal index for each data set to deliver 10x-100x faster performance compared to other data lake query engines. The platform used pre-defined materialization to enable indexing. This past spring, version 2.0 eliminated the need for materialization and added a dynamic, smart observability layer that automatically decides which data to index and when to index, making it easy to use and giving users a dramatic improvement in TCO (Total Cost of Ownership).
Version 3.0 extends these advantages with rapid and elastic scaling capabilities that let users add and remove nodes and clusters rapidly depending on current workload needs, further improving TCO for large-scale users.
Hot, Warm and Cold Data Layers Optimize Scaling Performance and TCO
Version 3.0 of the Varada platform includes three layers. The first is the hot data and index layer, in which SSD NVMe attached nodes (in the customer’s Virtual Private Cloud) are used to process queries and store hot data and cache for optimal performance. The second is the warm index and data layer, where an object storage bucket on the customer’s data lake is used to store all indexes for scaling purposes. The third layer is the customer data layer (“cold”), which remains the single source of truth.
When scaling in, indexes and data are not “lost” and continue to be available for other clusters and users. An index-once approach enables to speed up warm-up time by 10x-20x compared to indexing data from scratch. As new indexes are created by the platform, they are also stored in a designated folder on the customer’s data lake (“warm data”), in addition to the cluster’s SSDs in the “hot data” layer. When the cluster is scaled in or eliminated and some nodes are shut down, indexes remain available as warm data. Warm indexes enable fast warming up when scaling back out or when adding new clusters and adding SSD resources to the cluster. When scaling in, data admins keep the ability to start a cluster with the state and acceleration instructions of previously live clusters.
Varada’s platform is based on a multi-cluster approach, which allows different clusters to share warm indexed data by accessing the designated bucket on the data lake. In addition to behavior-based indexing, data platform teams can opt for indexing in the background by low-cost nodes on spot instances. Indexing will be stored on the “warm data” layer for fast warming up in the future. This can be used to prepare in advance for upcoming spikes in analytics requirements or to significantly reduce TCO.
*** Learn more about version 3 of the Varada platform. ***
About Varada
The Varada mission is to enable data practitioners to go beyond the traditional limitations imposed by data infrastructure and instead zero in on the data and answers they need—with complete control over performance, cost and flexibility. In Varada's world of big data, every query can find its optimal plan, with no prior preparation and no bottlenecks, providing consistent performance at a petabyte scale. Varada was founded by veterans of the Dell EMC XtremIO core team and is dedicated to leveraging the data lake architecture to take on the challenge of data and business agility. Varada has been recognized in the Cool Vendors in Data Management report by Gartner, Inc. For more information, visit: https://varada.io/
Contacts
Robert Cathey
Cathey Communications for Varada
robert@cathey.co
+1 865.386.6118