Data Virtualization Innovator Varada Raises $12 Million in Series A to Bring Full Access, Speed and Cost Control to Big Data Analytics
Data Virtualization Innovator Varada Raises $12 Million in Series A to Bring Full Access, Speed and Cost Control to Big Data Analytics
Varada to launch agile, ‘zero data-ops’ big data platform that gives organizations full visibility, cost management and data control
TEL AVIV, Israel--(BUSINESS WIRE)--Varada, a big data query acceleration innovator, announced today that it has closed a $12 million Series A round of funding. The round is led by MizMaa Ventures, an early-stage venture capital firm investing in Israeli technology startups, with participation by Gefen Capital. The round also included participation from existing investors Lightspeed, StageOne Ventures and F2 Venture Capital who contributed in early 2019 to a $7.5 million seed round.
The funding comes as Varada prepares to announce the general availability of its data virtualization platform, which will establish a new standard for accelerating big data workloads while optimizing control over performance and cost.
“In a world where every organization wants to be data-driven and data sources are growing exponentially in both volume and complexity, Data Virtualization and Data Lake technologies will be at the core strategy of any organization over the next 5 to 10 years,” said Aaron Applbaum, partner at MizMaa. “Varada disrupts this space with its unique and innovative indexing-based technology.”
“We have been working with the team for a couple of years and strongly believe that Varada brings a fresh approach to solving big data challenges,” added David Gussarsky, partner at Lightspeed. “Varada’s patented technology allows it to leap-frog the current state of the market, overcoming data control issues and offering far more sophisticated capabilities for prioritizing workloads to balance performance and cost.”
Tal Slobodkin, managing partner at StageOne Ventures observed that “Varada truly democratizes access to data and empowers data teams with deep visibility and seamless optimization to deliver the most effective data plan for any business requirement. Varada is making great strides, and we’re excited to participate again in this round.”
“Following the dev-ops revolution, data-ops is now at the center of attention of data executives,” explains Jonathan Saacks, managing partner at F2. “Varada’s zero data-ops approach offers data teams the ability to support any big data use case with very fast time-to-market while keeping tight control.”
The Problem Varada Solves
Data is the core of innovation and intellectual property for most organizations, constituting their strongest competitive advantage. Organizations must be able to collect, analyze and act on their data faster than their competitors while ensuring security and control of their data assets.
Following the cloud revolution, which put ease-of-use and agility as top priorities, the data space is driven by two emerging technologies: data lake and data virtualization. Until recently, companies typically stored data from different sources in separate silos which were disparately optimized for each workload. The data lake enables organizations to avoid extensive, pre-consumption ETLs (Extract, Transform, Load) and significantly cut down on time-to-market. With data virtualization, disparate data sources are unified and data consumers can now query any data from a single end-point. This eliminates the heavy IT operations burden of configuration, modeling and movement of data.
However, current data virtualization options are hamstrung by scaling limitations and often require extensive data-ops to meet the predictable and consistent performance data users demand. This is the problem Varada aims to solve.
“Varada is solving the biggest headaches of data infrastructure teams while giving business units the tools to quickly and cost effectively turn their priceless data assets into value for customers,” said Eran Vanounou, CEO of Varada. “I know this problem firsthand, as I was the CTO of LivePerson before joining Varada. When I met the founding team, I was blown away at their vision for how to solve one of the thorniest problems in big data. The platform we’re building enables revolutionary ease-of-use, fast time-to-market and cost control. This round of Series A funding will accelerate the progress of our solution and allow us to quickly scale our plans to deliver the new standard for data virtualization.”
Varada to Revolutionize Data Virtualization
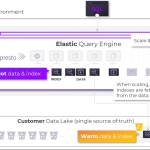
As the global big data market shifts to data lake based solutions, Varada is building a platform to revolutionize data virtualization by offering an agile, “zero data-ops” solution that gives the organization full visibility and control while serving a wider range of workloads including those that are latency-sensitive.
Varada’s patented indexing technology uses machine learning to accelerate relevant and high-priority queries automatically without any overhead to query processing or any data maintenance. Varada’s indexing works transparently for users, and indexes are managed automatically by Varada’s proprietary cost-based optimizer. Varada is able to identify which queries to accelerate and which indexes to maintain. These capabilities enable data teams to serve a wide range of business requirements with no operational overhead and truly deliver the promise of data virtualization.
About Varada
The Varada mission is to enable data practitioners to go beyond the traditional limitations imposed by data infrastructure and instead zero in on the data and answers they need—with complete control over performance, cost and flexibility. In Varada's world of big data, every query can find its optimal plan directly on the data lake, with no prior preparation and no bottlenecks, providing consistent performance at a petabyte scale. Varada was founded by David Krakov, Roman Vainbrand and Tal Ben Moshe, veterans of the Dell EMC XtremIO core team, and is dedicated to leveraging new architecture to take on the challenge of data and business agility. Headquarters are in Tel Aviv, with U.S. offices in San Mateo, Calif. More at https://varada.io/.
Contacts
Robert Cathey
Cathey Communications for Varada
robert@cathey.co