

Newsroom
Sorted by: Latest
-
ブロックストリーム・キャピタル・パートナーズ、Komainuとの戦略的提携を活用し、ヌメウス・グループのデリバティブ取引チームを戦略的に取得
ジャージー島セント・ヘリア--(BUSINESS WIRE)--(ビジネスワイヤ) -- ブロックストリーム・キャピタル・パートナーズ(「BCP」)は、ヌメウス・グループのデジタル資産取引・投資事業内の一部門を取得する戦略的合意を締結したと発表しました。本取引では、利回り創出に重点を置く一部のビットコインに特化した取引戦略を取り込むとともに、ボラティリティーとデリバティブ市場の専門家である最高投資責任者ディーパック・グラティ率いる10人のデリバティブ取引チーム受け入れる予定です。 ロドリゴ・ロドリゲスとともに、ブロックストリーム・キャピタル・マネジメントの共同最高投資責任者に就任したディーパック・グラティは、JPモルガンで自己勘定取引のグローバル責任者を務めた後、数十億ドル規模のボラティリティー特化型ヘッジファンドのアルジャン ティエール・キャピタルを設立しました。デリバティブがビットコインとデジタル資産市場の成熟を牽引するという仮説のもと、2021年にヌメウス・グループを共同設立し、機関投資家向けの取引・リスク管理・市場構造の高度化に取り組みました。BCPの既存の戦略投資先であるK...
-
Natera Announces Strong Preliminary Fourth Quarter and 2025 Financial Results Driven by Record Signatera™ Growth
AUSTIN, Texas--(BUSINESS WIRE)--Natera, Inc. (NASDAQ: NTRA), a global leader in cell-free DNA and precision medicine, today released preliminary unaudited results for the fourth quarter and full year ended December 31, 2025. The Company expects the following: Total revenues of approximately $660 million in the fourth quarter of 2025 compared to $476 million in the fourth quarter of 2024, an increase of approximately 39%. Total revenues, excluding revenue true-ups, were greater than $600 million...
-
ブロックブラスト!がDAU7,000万人を達成――Hungry Studio、1年間で1万件超の実験を実施
ニューヨーク--(BUSINESS WIRE)--(ビジネスワイヤ) -- Hungry Studio のフラッグシップタイトルである、ブロックブラスト!は、 DAU7,000万人およびMAU3億人に到達しました。世界規模で展開されており、その規模は、ゲームプレイ、進行設計、ユーザー体験全体にわたって1年間で1万件以上実施されたA/Bテストによる実験体制によって支えられています。 ブロックブラスト!は、クラシックなブロックベースのメカニクスを基盤として構築されており、 直感的な「ドラッグ・マッチ・消去」の体験を提供しており、簡単に遊べる一方で、長期的なエンゲージメントを前提とした設計となっています。2021年のリリース以降、本作は単一モードのパズルゲームから、アクセシビリティと継続的な挑戦性を両立したマルチモード体験へと進化してきました。 「この規模の背後には、プレイヤー体験を継続的に改善するための厳格な実験体制が存在します。ブロックブラスト!は一見シンプルに見えますが、実際には大規模なA/Bテストフレームワークによって支えられています」と述べたのは、Hungry Studio ブラ...

-
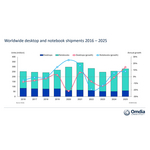
Omdia: Global PC Shipments Grew 9% in 2025 but Memory and Storage Supply Issues Threaten 2026 Outlook
LONDON--(BUSINESS WIRE)--The latest research from Omdia reveals that total shipments of desktops, notebooks and workstations in Q4 2025 grew 10.1% to 75 million units. This brought full-year 2025 PC shipments to 279.5 million units, a 9.2% increase over 2024 volumes. Notebook (including mobile workstation) shipments reached 58.6 million units in Q4 and 220.4 million units in the full year, achieving 8% growth in 2025. Desktop (including desktop workstation) shipments in Q4 landed at 16.2 millio...
-
FPT Software Positioned as a Leader in IDC MarketScape Report for AI-Enabled Front Office Conversational AI Software in Asia-Pacific
HANOI, Vietnam--(BUSINESS WIRE)--FPT Software, the global IT services subsidiary of FPT Corporation (FPT), is positioned as a Leader in the IDC MarketScape: Asia/Pacific AI-Enabled Front Office Conversational AI Software 2025 Vendor Assessment (doc # AP52998625e, November 2025). The IDC MarketScape evaluates 17 vendors in the Asia/Pacific region based on two major criteria: capability and strategy. Key factors include functionality, innovation in conversational AI, long-term vision, infrastruct...

-
Nattakorn Wattanaumphaipong Joins Great American Insurance Company’s Singapore Branch
SINGAPORE & CINCINNATI--(BUSINESS WIRE)--Great American is pleased to announce the hiring of Nattakorn Wattanaumphaipong as Senior Director, Technical Underwriting for the Singapore Branch....

-
Ant International Partners with Google’s Universal Commerce Protocol to Expand AI Capabilities
SINGAPORE--(BUSINESS WIRE)--Ant International is collaborating with Google on the launch of its Universal Commerce Protocol (UCP), a new open standard for agentic commerce....
-
CDB Aviation Signs New Sustainability Linked Unsecured Term Loan for $710 Million
DUBLIN--(BUSINESS WIRE)--CDB Aviation executed a new Sustainability Linked Loan transaction anchored with a five-year $710 million unsecured term loan facility....
-
UPPF Opens Shanghai Technical Center to Accelerate Product Support, Quality Management, and Installer Training
SHANGHAI--(BUSINESS WIRE)--UPPF announced the grand opening of its Technical Center in Shanghai, a 3,000 sq ft facility designed to deliver faster, more comprehensive product support, strengthen quality management, and expand installation training for dealers and partners across Asia and beyond. The new center aligns with UPPF’s commitment to practical innovation and customer success, captured in the event theme: “Your Growth, Our Mission.” “This Technical Center is built to help our customers...

-
SNCY Stock Alert: Halper Sadeh LLC is Investigating Whether the Sale of Sun Country Airlines Holdings, Inc. is Fair to Shareholders
NEW YORK--(BUSINESS WIRE)--Halper Sadeh LLC, an investor rights law firm, is investigating whether the sale of Sun Country Airlines Holdings, Inc. (NASDAQ: SNCY) to Allegiant Travel Company for 0.1557 shares of Allegiant common stock and $4.10 in cash for each Sun Country share is fair to Sun Country shareholders. Halper Sadeh encourages Sun Country shareholders to click here to learn more about their legal rights and options or contact Daniel Sadeh or Zachary Halper at (212) 763-0060 or sadeh@...