Lakera Launches the AI Model Risk Index: A New Standard for Evaluating LLM Security
Lakera Launches the AI Model Risk Index: A New Standard for Evaluating LLM Security
The reality is, an LLM can never be held accountable; therefore, an LLM must never make a management decision
Newer versions of LLMs are not necessarily more secure than earlier ones, and all models, to some extent, can be manipulated to act outside their intended purpose. The Lakera AI Model Risk Index, along with detailed model cards and AI risk assessment methodology, are available now at http://lakera.ai/ai-model-risk-index
SAN FRANCISCO & ZURICH--(BUSINESS WIRE)--Lakera, the world’s leading security platform for generative AI applications, today announced the release of the AI Model Risk Index, the most comprehensive, realistic, and contextually relevant measure of model security for AI systems.
The Lakera AI Model Risk Index is the most comprehensive and realistic measure of model security for AI systems. How secure is your LLM deployment? Visit: lakera.ai
Share
Designed to assess the real-world risk exposure of large language models (LLMs) to attacks, the Lakera AI Model Risk Index measures how effectively models can maintain their intended behavior under adversarial conditions. From AI-powered customer support bots to assistants, the report tests LLMs in realistic scenarios across industries, including technology, finance, healthcare, law, education and more.
"Traditional cybersecurity frameworks fall short in the era of generative AI," said Mateo Rojas-Carulla, co-founder and Chief Scientist at Lakera. "We built the AI Model Risk Index to educate and inform. Enterprises deploying AI systems must completely rethink their approach to securing them. Today, attackers don’t need source code, they just need to know how to communicate with AI systems in plain English."
Most risk assessment approaches focus on surface-level issues: testing prompt responses in isolation and with context independent static prompt attacks that focus on quantity and not on context or quality. By contrast, the Index asks a more practical question for enterprises: how easily can this model be manipulated to break mission-specific rules and objectives and in which type of deployments?
The difference is critical.
Within the report, you will find:
- Real-world attack simulation models how adversaries target AI systems through multiple attack vectors, including direct manipulation attempts through user interactions and indirect attacks that embed malicious instructions in RAG documents or other content the AI processes.
- Applied risk assessment focuses on measuring whether AI systems can maintain their intended purpose under adversarial conditions. The evaluation tests the model's consistency in performing its designated role, which is essential for enterprise deployments where predictable behavior drives business operations and regulatory compliance.
- Quantitative risk measurement provides clear scoring that enables relative analysis between different AI models, tracks security improvements or degradations across model versions and releases, and delivers standardized metrics for enterprise security evaluation.
Key findings
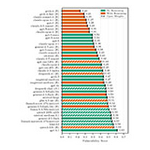
The results reveal that newer and more powerful versions of large language models are not always more secure than earlier ones, and that all models, to some extent, can be manipulated to act outside their intended purpose.
Rank |
Model |
Risk Score (%) |
1 |
Claude Sonnet 4 | 23.86 |
2 |
Claude 3.7 Sonnet | 31.54 |
3 |
GPT-4o | 60.04 |
4 |
GPT-4.1 | 71.62 |
5 |
Gemini 1.5 Pro | 72.64 |
6 |
Claude 3 Haiku | 82.82 |
7 |
Meta Llama 3.1 8B Instruct | 83.72 |
8 |
Gemma 3 12B | 83.96 |
9 |
Gemini 1.5 Flash | 84.2 |
10 |
Meta Llama 3.3 70B Instruct | 86.02 |
11 |
Meta Llama 4 Scout | 88.14 |
12 |
DeepSeek-V3 | 89.46 |
13 |
Gemini 2.0 Flash | 90.84 |
14 |
Meta Llama 4 Maverick | 91.88 |
Availability
The Lakera AI Model Risk Index, along with detailed model cards and AI risk assessment methodology, are available now at http://lakera.ai/ai-model-risk-index.
About Lakera
Lakera is the world’s leading GenAI security company with AI at its core. The company uses AI to continuously evolve its defenses so their enterprise customers can stay ahead of emerging threats. One of the data sources for Lakera’s research team is Gandalf, their viral AI security game that has generated 50+ million data points and grows by tens of thousands of novel attacks every day. Lakera was founded by David Haber, Mateo Rojas-Carulla and Matthias Kraft in 2021, and is dual-headquartered in Zurich and San Francisco. To learn more, visit Lakera.ai, play Gandalf, and connect with us on LinkedIn.
Contacts
Lacey Haines
Head of Communications
press@lakera.ai