

Inspur AI Research Presents Yuan 1.0 — One of the World’s Largest Language Models with 245.7 Billion Parameters
Inspur AI Research Presents Yuan 1.0 — One of the World’s Largest Language Models with 245.7 Billion Parameters
Inspur’s Yuan 1.0 language model has 245.7 billion parameters and has been trained with 5 TB of datasets. Its parallel GPU computing and excellent performance in zero-shot and few-shot learning gives it the ability to generate language content that is difficult to distinguish from human-generated content.
SAN JOSE, Calif.--(BUSINESS WIRE)--The Inspur Artificial Intelligence Research Institute (Inspur AI Research) unveiled the language model Yuan 1.0 at a large-scale AI model workshop in Beijing on September 28, 2021. It was released as the largest language model in the world with 245.7 billion parameters and 5 TB of datasets. Yuan 1.0 showcased impressive performance in both zero-shot and few-shot learning along with its ability to generate language content that is oftentimes indistinguishable from human-generated content. An academic paper detailing the development and optimization of Yuan 1.0 and its related testing results has been published on arXiv.
Inspur built Yuan 1.0 from the ground up as a Chinese-language model, which required a unique development approach compared to English. This included handling Chinese-specific challenges like tokenizing sentences with the absence of spaces and the lack of a prior high-quality Chinese-language corpus to work from.
To handle the amount of processing power required, a large-scale distributed training system was incorporated into the fundamental design architecture of Yuan 1.0 with training spread across 2128 GPUs.
Yuan 1.0’s distributed training system gave it top ranking in both ZeroCLUE and FewClue for the Chinese Language Understanding Evaluation Benchmark (CLUE). In ZeroCLUE, Yuan 1.0 scored 18.3% higher than the previous record and ranked first in 6 tasks: scientific literature subjects classification, news classification, product classification, natural language inference, idiom reading comprehension, and noun-pronoun relationships. In FewCLUE, Yuan 1.0 ranked first in 4 tasks: scientific literature subjects classification, product classification, scientific literature abstract and keywords recognition, and noun-pronoun relationships. Notably, in the idiom reading comprehension task, Yuan 1.0 surpassed human ability.
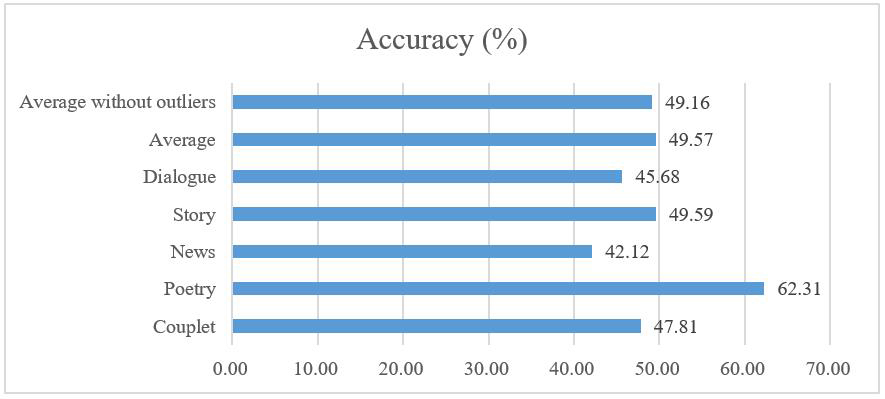
Yuan 1.0 is extremely adept at natural language generating (NLG) tasks. It is capable of generating written content that can passes the Turing Test. Human participants were only able to distinguish Yuan 1.0 generated dialogues, novel continuations, news articles, poems, and couplets from human-generated content less than 50% of the time.
Yuan 1.0’s excellent performance and advanced NLG capabilities stem from multiple optimizations across three major areas: model architecture, results calibration, and dataset creation.
Model Architecture
In terms of model architecture, the large-scale distributed training in Yuan 1.0 combines three different parallelism strategies: tensor, pipeline, and data parallelism. To maximize the effectiveness of using computational resources, the model takes into account parameters that will offer optimal results and prioritizes computational resources to these parameters. These architecture optimizations allow 245.7 billion parameters to be calculated with 4095 PetaFlop-days of processing power while only sustaining a training loss of 1.64.
Results calibration
Inspur AI Research noticed that there is bias towards template sentences and labels with in-context learning. This bias mainly stems from distribution imbalances in the dataset between classes, few-shot examples with a certain order, and labels with different frequencies in the training corpus. To minimize the impact of bias, Inspur developed a two-pronged calibration method for in-context learning: a calibration on the calculation of probability and an expansion of labels. This results in observable improvements in learning accuracy over time.
Dataset Creation
Inspur developed a Massive Data Filtering System (MDFS) built upon Spark to clean and filter raw data and train a BERT-based model to select high quality text samples. MDFS consists of three stages: data collection, course filtering, and fine tuning. MDFS built the 5 TB corpus used by Yuan 1.0 by filtering 850 TB of raw data collected from the internet. This was achieved by running MDFS on a high performance cluster with 36 nodes. The resulting corpus is the largest high-quality Chinese corpus in the world.
To view the complete paper, please visit https://arxiv.org/abs/2110.04725
About Inspur AI Research
The Inspur Artificial Intelligence Research Institute focuses on promoting innovations in the area of cutting-edge AI technology via research in foundational science, forward-looking technology, and applied technology. Since its foundation, the Inspur Artificial Intelligence Research Institute has generated numerous achievements in exploring cognitive intelligence and promoting the application of AI in industries.
Contacts
Press:
Fiona Liu
Inspur Information
liuxuan01@inspur.com
