
")
SAN JOSE, Calif.--(BUSINESS WIRE)--MLCommons™, a well-known open engineering consortium, released the results of MLPerf™ Inference v2.0, the leading AI benchmark suite. Inspur AI servers set records in all 16 tasks in the data center Closed division, showcasing the best performance in real-world AI application scenarios.
MLPerf™ was established by Turing Award winner David Patterson and top academic institutions. It is leading AI performance benchmark in the world, organizing AI inference and AI training tests twice a year to track and evaluate rapidly-growing AI development. MLPerf™ has two divisions: Closed and Open. The Closed division provides an apples-to-apples comparison between vendors because it requires the use of the same model and optimizer, making it an excellent reference benchmark.
The first AI inference benchmark of MLPerf™ in 2022 aimed to examine the inference speed and capabilities of computing systems of different manufacturers in various AI tasks. The Closed division for the data center category is the most competitive division. A total of 926 results were submitted, double the submissions from the previous benchmark.
Inspur AI servers set new records in inference performance
The MLPerf™ AI inference benchmark covers six widely used AI tasks: image classification (ResNet50), natural language processing (BERT), speech recognition (RNN-T), object detection (SSD-ResNet34), medical image segmentation (3D-Unet) and recommendation (DLRM). MLPerf™ benchmarks require an accuracy of more than 99% of original model. For natural language processing, medical image segmentation and recommendation, two accuracy targets of 99% and 99.9% are set to examine the impact on the computing performance when improving the quality target of AI inference.
In order to more closely match real-world usage, the MLPerf™ inference tests have two required scenarios for the data center category: offline and server. Offline scenarios mean that all data required for the task is available locally. The server scenario has data delivered online in bursts when requested.
Inspur Information Results in MLPerfTM Inference v2.0 |
||||||||||
Submitter |
Division |
Task |
Model |
Result |
Units |
Accuracy |
Scenario |
|||
Inspur
|
Data
|
Image
|
ResNet50 |
449,856 |
samples/s |
99% |
Offline |
|||
400,583 |
queries/s |
99% |
Server |
|||||||
Natural
|
BERT |
38,776.7 |
samples/s |
99% |
Offline |
|||||
35,487.4 |
queries/s |
99% |
Server |
|||||||
19,370.4 |
samples/s |
99.9% |
Offline |
|||||||
16,790.5 |
queries/s |
99.9% |
Server |
|||||||
Speech
|
RNN-T |
155,811 |
samples/s |
99% |
Offline |
|||||
136,498 |
queries/s |
99% |
Server |
|||||||
Object
|
SSD-
|
11,081.9 |
samples/s |
99% |
Offline |
|||||
10,893.4 |
queries/s |
99% |
Server |
|||||||
Medical image
|
3D-Unet |
36.25 |
samples/s |
99% |
Offline |
|||||
36.25 |
samples/s |
99.9% |
Offline |
|||||||
Recommendation |
DLRM |
2,645,980 |
samples/s |
99% |
Offline |
|||||
2,683,620 |
queries/s |
99% |
Server |
|||||||
2,645,980 |
samples/s |
99.9% |
Offline |
|||||||
2,683,620 |
queries/s |
99.9% |
Server |
|||||||
Inspur AI server set a performance record of processing 449,856 images per second in the ResNet50 model task, which is equivalent to completing the classification of 1.28 million images in the ImageNet dataset in only 2.8 seconds. In the 3D-UNet model task, Inspur set a new record for processing 36.25 medical images per second, which is equivalent to completing the segmentation of 207 3D medical images in the KiTS19 dataset within 6 seconds. In the SSD-ResNet34 model task, Inspur set a new record of completing the target object recognition and identification of 11,081.9 images per second. In the BERT model task, Inspur set a performance record of completing 38,776.7 questions and answers per second on average. In the RNNT model task, Inspur set a record of completing 155,811 speech recognition conversions per second on average, and Inspur set the best record of completing 2,645,980 click predictions per second on average in the DLRM model task.
In Edge inference category, Inspur's AI servers designed for edge scenarios also performed well. NE5260M5, NF5488A5, and NF5688M6 won 11 titles out of 17 tasks in the Closed division.
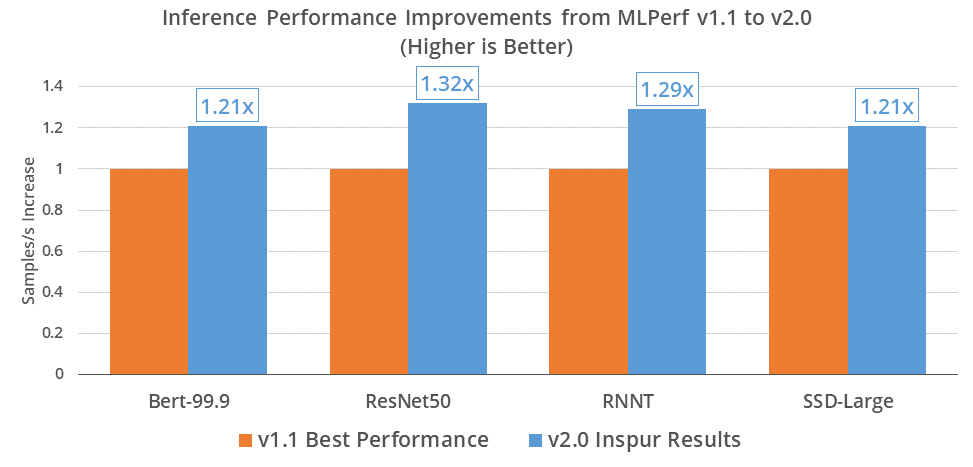
With the continuous development of AI applications, faster inference processing will bring higher AI application efficiency and capabilities, accelerating the transformation to intelligent industries. Compared with the MLPerf™ AI inference v1.1, Inspur AI servers have improved image classification, speech recognition and natural language processing tasks by 31.5%, 28.5% and 21.3% respectively. These results mean that Inspur AI server can complete various AI tasks more efficiently and rapidly in scenarios such as autonomous driving, voice conferences, intelligent question and answer, and smart medical care.
Full-stack optimization boosts continuous improvement in AI performance
The outstanding performance of Inspur AI servers in the MLPerf™ benchmarks is due to Inspur Information's excellent system design capabilities and full-stack optimization capabilities in AI computing systems.
The Inspur AI server NF5468M6J can support 12x NVIDIA A100 Tensor Core GPUs with a layered and scalable computing architecture, and set 12 MLPerf™ records. Inspur Information also offers servers supporting 8x 500W NVIDIA A100 GPUs by utilizing liquid and air cooling. Among high-end mainstream models adopting 8x NVIDIA GPUs with NVLink in this benchmark, Inspur AI servers achieved the best results in 14 of 16 tasks in the data center category. Among them, NF5488A5 supports 8x third-generation NVlink A100 GPUs and 2x AMD Milan CPUs in a 4U space. NF5688M6 is an AI server with extreme scalability optimized for hyperscalers. It supports 8x NVIDIA A100 GPUs and 2x Intel Icelake CPUs, and supports up to 13x PCIe Gen4 IO expansion cards.
In the Edge inference category, the NE5260M5, comes with optimized signaling and power systems, and offers widespread compatibility with high-performance CPUs and a wide range of AI accelerator cards. It features a shock-absorbing and noise-reducing design, and has undergone rigorous reliability testing. With a chassis depth of 430 mm, nearly half the depth traditional servers, it is deployable even in space-constrained edge computing scenarios.
Inspur AI servers makes optimized data path between the CPU and GPU through fine calibration and comprehensive optimization of the CPU and GPU hardware. At the software level, by enhancing the round-robin scheduling for multiple GPUs based on GPU topology, the performance of a single GPU or multiple GPUs can be increased nearly linearly. For deep learning, based on computing characteristics of NVIDA GPU Tensor Core unit, performance optimization of the model is achieved through an Inspur-developed channel compression algorithm.
To view the complete results of MLPerf™ Inference v2.0, please visit:
https://mlcommons.org/en/inference-datacenter-20/
https://mlcommons.org/en/inference-edge-20/
About Inspur Information
Inspur Information is a leading provider of data center infrastructure, cloud computing, and AI solutions. It is the world’s 2nd largest server manufacturer. Through engineering and innovation, Inspur Information delivers cutting-edge computing hardware design and extensive product offerings to address important technology sectors such as open computing, cloud data center, AI, and deep learning. Performance-optimized and purpose-built, our world-class solutions empower customers to tackle specific workloads and real-world challenges. To learn more, visit https://www.inspursystems.com.